
B tree index files
A B tree index files could be a methodology of putting and locating files (called records or keys) in an exceedingly database. (The which means of the letter B has not been explicitly defined.) The B tree index files algorithm minimizes the quantity of times a medium should be accessed to locate a desired record, thereby dashing up the process
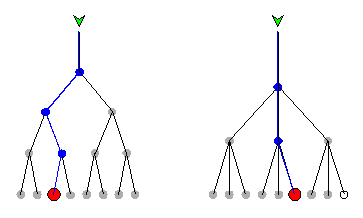 |
B tree index files are most well-liked once decision points, known as nodes, are on disk instead of in random-access memory (RAM). It takes thousands of times longer to access a knowledge component from disk as compared with accessing it from RAM, as a result of a drive has mechanical components, that read and write information way more slowly than strictly electronic media. B-trees save time by victimization nodes with several branches (called children), compared with binary trees, within which every node has solely 2 children. once there are several children per node, a record will be found by passing through fewer nodes than if there are 2 children per node. A simplified example of this principle is shown below.
In a tree, records are keep in locations known as leaves. This name derives from the very fact that records forever exist at finish points; there’s nothing on the far side them. the utmost variety of children per node is that the order of the tree. the quantity of needed disk accesses is that the depth. The image at left shows a binary tree for locating a selected record in an exceedingly set of eight leaves. The image at right shows a B tree index files of order 3 for locating a selected record in an exceedingly set of eight leaves (the ninth leaf is unoccupied, and is named a null). The binary tree at left features a depth of four; the B-tree at right features a depth of 3. Clearly, the B-tree permits a desired record to be situated quicker, forward all alternative system parameters are identical. The trade-off is that the choice method at every node is additional difficult in an exceedingly B-tree as compared with a binary tree. a classy program is needed to execute the operations in an exceedingly B-tree. however this program is keep in RAM, thus it runs quick.
In a sensible B tree index files, there will be thousands, millions, or billions of records. Not all leaves essentially contain a record, however a minimum of 1/2 them do. The distinction in depth between binary-tree and B tree index files schemes is larger in an exceedingly sensible database than within the example illustrated here, as a result of real-world B-trees are of upper order (32, 64, 128, or more). counting on the quantity of records within the info, the depth of a B-tree will and sometimes will amendment. Adding an oversized enough variety of records can increase the depth; deleting an oversized enough variety of records can decrease the depth. This ensures that the B-tree functions optimally for the quantity of records it contains.
Advantages:
Lack of redundant storage (but solely marginally different).
Some searches are quicker (key could also be in non-leaf node).
Disadvantages:
Leaf and non-leaf nodes are of various size (complicates storage)
Deletion might occur in an exceedingly non-leaf node (more complicated)